iOS 界面渲染
type
status
date
slug
summary
tags
category
icon
password
介绍
这篇文章主要讨论 iOS 中界面渲染的流程,以及
UIView 以及 CALayer 这两个 iOS 中最基础的类的相关知识。了解渲染知识,是为了在遇到 App 卡顿以及掉帧问题的时候,我们可以通过界面渲染的原理迅速定位到原因,从而更快的解决问题。
在阅读这篇文章之前,建议先了解屏幕成像的原理,可以参考 iOS 保持界面流畅的技巧 | Garan no dou 和图形图像渲染原理。UIView 与 CALayer
在了解 iOS 界面渲染流程之前,我们先来深入了解一下我们开发中最常用的最基础的 UIView 和 CALayer。
UIView
UIView 继承自
UIResponder, 主要负责事件响应,属于 UIKit 框架。UIView 的职责是创建并管理图层,以确保当子视图在层级关系中添加或被移除时,其关联的图层在图层树中也有相同的操作,即保证视图树和图层树在结构上的一致性。
UIView 本身不具备图像渲染能力的,拥有一个 layer 属性用来持有一个 CALayer 实例,我们平时操作的 UIView 的绝大部分绘图属性内部其实都是操作其拥有的 layer 属性,比如 frame、hidden 等。UIView 还有一个
layerClass 属性,均为只读属性,其中:layer属性返回的是 UIView 所持有的主 Layer(RootLayer) 实例,我们可以通过其来设置 UIView 没有封装的一些 layer 属性;
layerClass则返回 RootLayer 所使用的类,我们可以通过重写该属性,来让 UIView 使用不同的 CALayer 来显示。
之所以设计成 UIView 和 CALayer 提供两个平行的层级关系,原因在于要做 职责分离,这样也能避免很多重复代码。在 iOS 和 Mac OS X 两个平台上,事件和用户交互有很多地方的不同,基于多点触控的用户界面和基于鼠标键盘的交互有着本质的区别,这就是为什么 iOS 有UIKit和UIView,对应 Mac OS X 有AppKit和NSView的原因。它们在功能上很相似,但是在实现上有着显著的区别。
CALayer
CALayer 继承自
NSObject, 负责图像渲染,属于 QuartzCore 框架。CALayer 视图结构类似 UIView 的子 View 树形结构,它们分别可以有自己的 SubView 和 SubLayer,可以向它的 RootLayer 上添加子 layer,来完成一些页面效果,比如说渐变等。
Layer 相对 View 来说是更加轻量的,所以当显示部分不需要事件响应时,我们可以优先考虑使用 layer。
为什么 CALayer 可以呈现可视化内容呢?因为 CALayer 基本等同于一个 纹理。纹理是 GPU 进行图像渲染的重要依据。 CALayer 包含一个 contents 属性指向一块缓存区,称为 backing store,可以存放位图(Bitmap)。iOS 中将该缓存区保存的图片称为 寄宿图。而当设备屏幕进行刷新时,会从 CALayer 中读取生成的 bitmap ,进而呈现到屏幕上。
图形渲染流水线支持从顶点开始进行绘制(在流水线中,顶点会被处理生成纹理),也支持直接使用纹理(图片)进行渲染。相应地,在实际开发中,绘制界面也有两种方式:一种是 手动绘制;另一种是 使用图片。
对应的实现方式:
- 使用图片:contents image
这种方式就是我们平时常见的
UIImageView 显示的形式,我们通过 CALayer 的 contents 属性来配置图片。contents 属性的类型为 id,在这种情况下,可以给 contents 属性赋予任何值,项目仍可以编译通过。但是在实践中,如果 content 的值不是 CGImage ,得到的图层将是空白的。之所以将contents的属性类型定义为id而非CGImage。这是因为在 Mac OS 系统中,该属性对CGImage和NSImage类型的值都起作用,而在 iOS 系统中,该属性只对CGImage起作用。
- 手动绘制:custom drawing
Custom Drawing 是指使用
Core Graphics 直接绘制寄宿图。实际开发中,一般通过继承 UIView 并实现 -drawRect: 方法来自定义绘制。具体什么时候会调用 -drawRect: ,我们在下面渲染流程中会说到。渲染流程
了解了UIView和CALayer,我们来看一下 iOS 上的图形渲染框架,下图自顶而下的展示了不同的层级结构。

整个渲染架构大致分4层:
UIKit
常用的视图层框架,供APP应用层使用。
Core Animation
图形渲染和动画的基础,负责组合屏幕上不同的可视内容 layer ,存储为树状层级结构
layer tree。
Metal/Core GraphicsMetal 负责处理 GPU 渲染(以前用的是 OpenGL ES );
Core Graphics负责处理 CPU 渲染。
Graphics HardWare图形硬件操作。
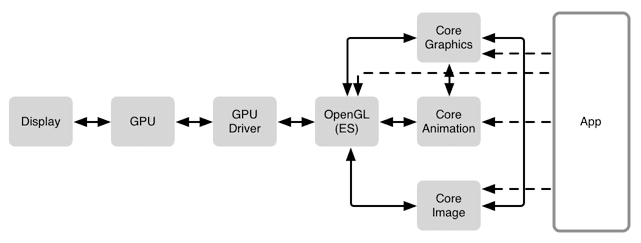
结合上面这张图,我们能了解 iOS 上的图形渲染方式,App 最上层使用的是 UIKit,在其之下使用
Core Graphics、Core Animation、Core Image 等框架来绘制可视化内容,这些软件框架相互之间也有着依赖关系。这些框架都需要通过 OpenGL 来调用 GPU 进行绘制,最终将内容显示到屏幕之上。Core Animation Pipeline
接下来我们来看一下 Core Animation Pipeline 渲染流水线,一共分为6个过程。
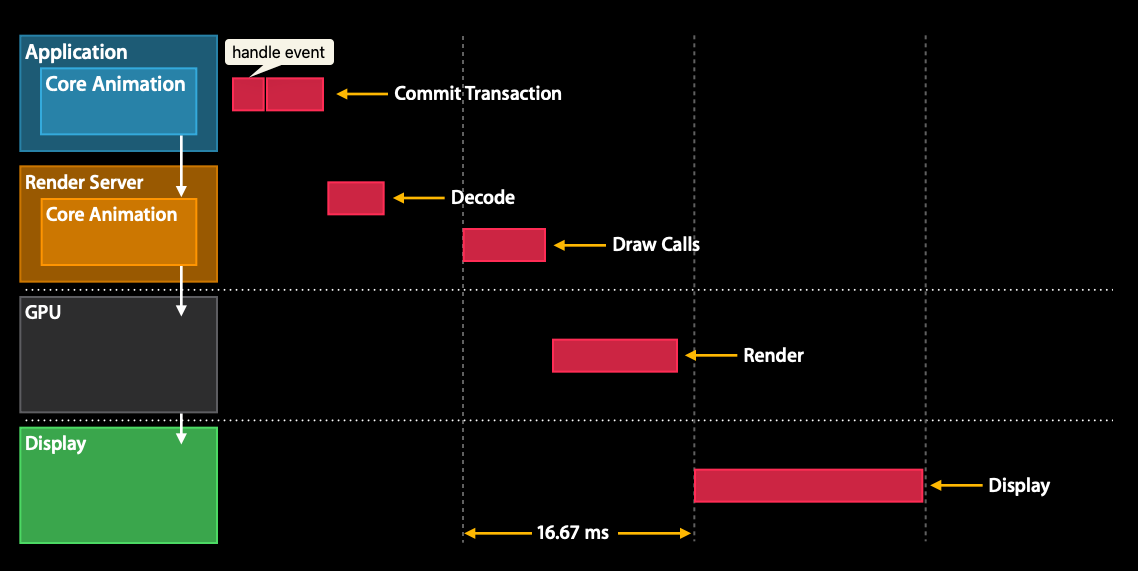
1. Handle Events
APP 响应事件,可能会改变布局和界面层次,这一步工作在 CPU 上。
2. Commit Transaction
APP 通过
Core Animation 处理显示内容,比如布局计算、图片解码等,之后把计算好的图层树 layer tree 编码打包发给 Render Server,这一步工作在 CPU 上。
3. Decode
Render Server 收到打包好的图层树,调用 Core Animation 进行解码,这一步工作在 CPU 上。
4. Draw Calls
解码完成后,Core Animation 会调用下层渲染框架(OpenGL ES / Metal)生成 Draw Calls 绘制调用,告诉 GPU 需要渲染的信息,包含 primitives 图元信息,由 CPU 发起。
了解 Draw Calls,可以看这个 视频 。
5. Render
渲染,准备 frame buffer/back buffer 缓冲区数据,等待下一个垂直信号 VSync 来读取 frame buffer/back buffer 缓冲区数据,这一步工作在 GPU 上。
6. Display
屏幕显示,视频控制器读取帧缓冲区的数据,交给显示器显示。Commit Transaction
由上面的流程我们可以看到,在开发中我们可以影响到的主要就是 Handle Events 和 Commit Transaction 这两个阶段,一般我们做优化和调试也是在这两个阶段。Handle Events 就是处理触摸事件,而 Commit Transaction 这部分中主要进行的是:Layout、Display、Prepare、Commit 等四个具体的操作。

1. Layout:构建视图
这个阶段主要处理视图的构建和布局,具体步骤包括:
- 调用重载的
layoutSubviews方法
- 创建视图,并通过
addSubview方法添加子视图
- 计算视图布局,即所有的 Layout Constraint
由于这个阶段是在 CPU 中进行,通常是 CPU 限制或者 IO 限制,所以我们应该尽量高效轻量地操作,减少这部分的时间,比如减少非必要的视图创建、简化布局计算、减少视图层级等。
2. Display:绘制视图
这个阶段主要是交给 Core Graphics 进行视图的绘制,注意不是真正的显示,而是得到图元
primitives 数据,通常是三角形、线段、顶点等:- 根据上一阶段 Layout 的结果创建得到图元信息。
- 如果重写了
drawRect:方法,那么会调用重载的drawRect:方法,在drawRect:方法中手动绘制得到 bitmap 数据,从而自定义视图的绘制。
注意正常情况下 Display 阶段只会得到图元
primitives 信息,而位图 bitmap 是在 GPU 中根据图元信息绘制得到的。但是如果重写了 drawRect: 方法,这个方法会直接调用 Core Graphics 绘制方法得到 bitmap 数据,同时系统会额外申请一块内存,用于暂存绘制好的 bitmap。
由于重写了 drawRect: 方法,导致绘制过程从 GPU 转移到了 CPU,这就导致了一定的效率损失。与此同时,这个过程会额外使用 CPU 和内存,因此需要高效绘制,否则容易造成 CPU 卡顿或者内存爆炸。3. Prepare:Core Animation 额外的工作
这一步主要是:图片解码和转换。
4. Commit:打包并发送
这一步主要是:图层打包并发送到 Render Server。
注意 commit 操作是依赖图层树递归执行的,所以如果图层树过于复杂,commit 的开销就会很大。这也是我们希望减少视图层级,从而降低图层树复杂度的原因。
Tile Based Rendering Rendering Pass
当
Render Server 收到 Commit Transaction 提交过来的图层树 layer tree 之后,会先交给 Core Animation 的 Decode 解码,再调用 Metal/OpenGL 生成 Draw Calls 绘制调用,交给 GPU,执行 Render。
接下来我们看下 Render 的具体过程,如下图: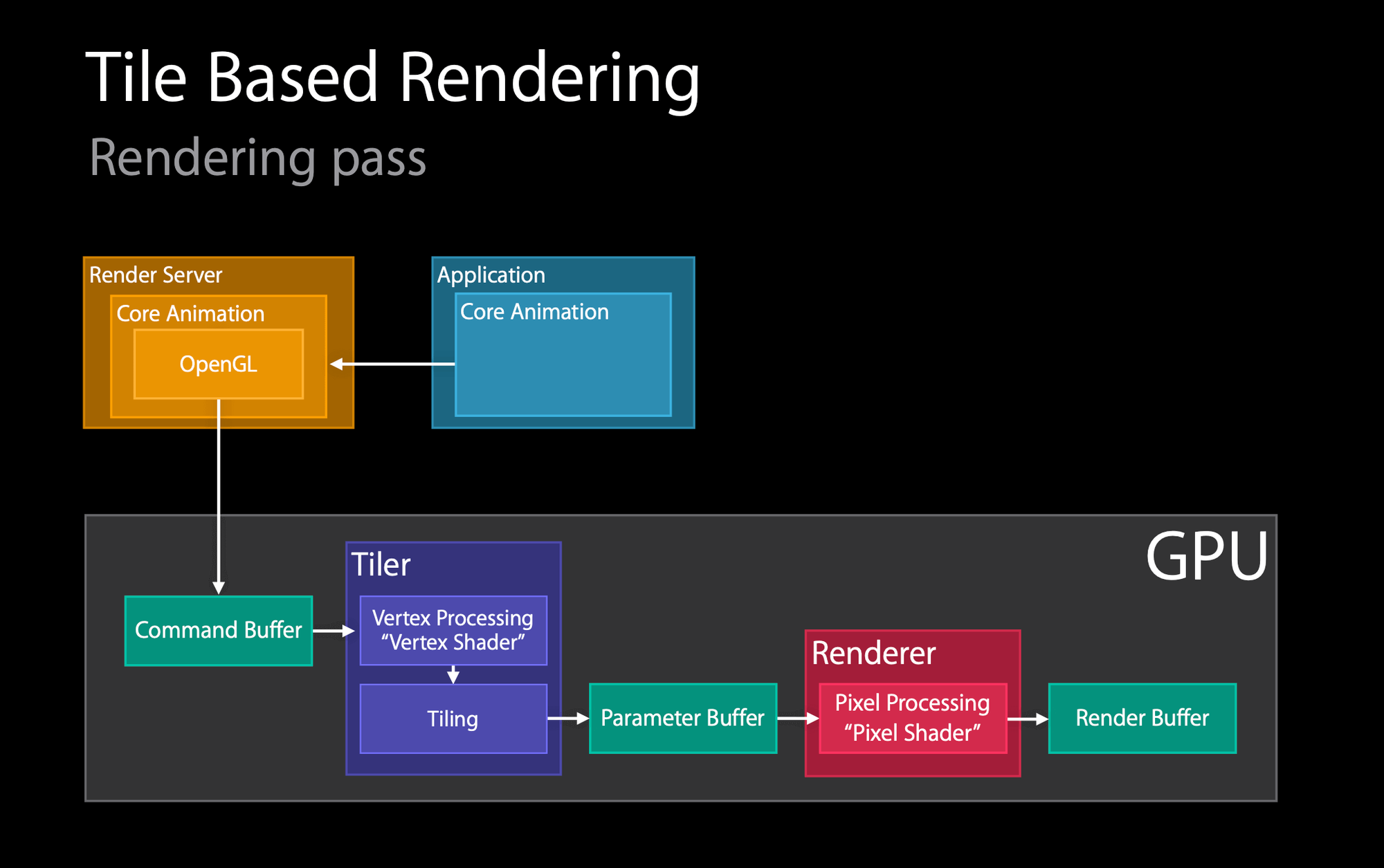
- GPU 收到
Command Buffer,即OpenGL/Metal的渲染指令,包含图元 primitives 信息。
- Tiler,调用顶点着色器,把顶点数据进行分块(Tiling),存储到
Parameter Buffer中。
- Renderer,调用片元着色器,进行像素渲染,得到
bitmap,存储到Render Buffer。
- 最后交给
Display显示。
UIView的绘制原理
上面我们已经从全局的角度了解了界面渲染的流程,但是如果没有将知识和实际开发结合起来,那这些知识也仅仅是停留在理论中,没有任何的意义,所以接下来我们结合代码层面,看看具体的运行逻辑。
我们知道,UIView 有两个容易搞混的方法,setNeedsLayout 和 setNeedsDisplay,这两个函数的区别在于:
- SetNeedsLayout
使当前 View 的 Layout 布局失效,并且对 CALayer 进行标记,在下一个更新周期触发布局更新,这个更新的过程对应我们上面 Commit Transaction 中的第一个步骤 Layout。此时如果主动调用
LayoutIfNeed 将会立即触发布局的更新。
通过 Layout 的流程我们知道在这之后会调用重载的 layoutSubviews 方法,创建视图,并通过 addSubview 方法添加子视图,计算视图布局,即所有的 Layout Constraint。
为什么说直接代码设置 frame 的方式性能要好于使用 autoLayout,主要原因是直接设置 frame 我们已经提前计算好了 Layer 的位置和大小,如果不重写 layoutSubviews,那么系统的 layoutSubviews 什么都不需要做。而使用 autolayout,用代码将布局的规则描述出来,具体的计算交给系统去做,自然会多消耗一些性能。- SetNeedsDisplay
将 View 的整个区域范围标记为需要重新绘制,view 将在下一个绘制周期进行重绘。具体的 API 调用流程如下图:
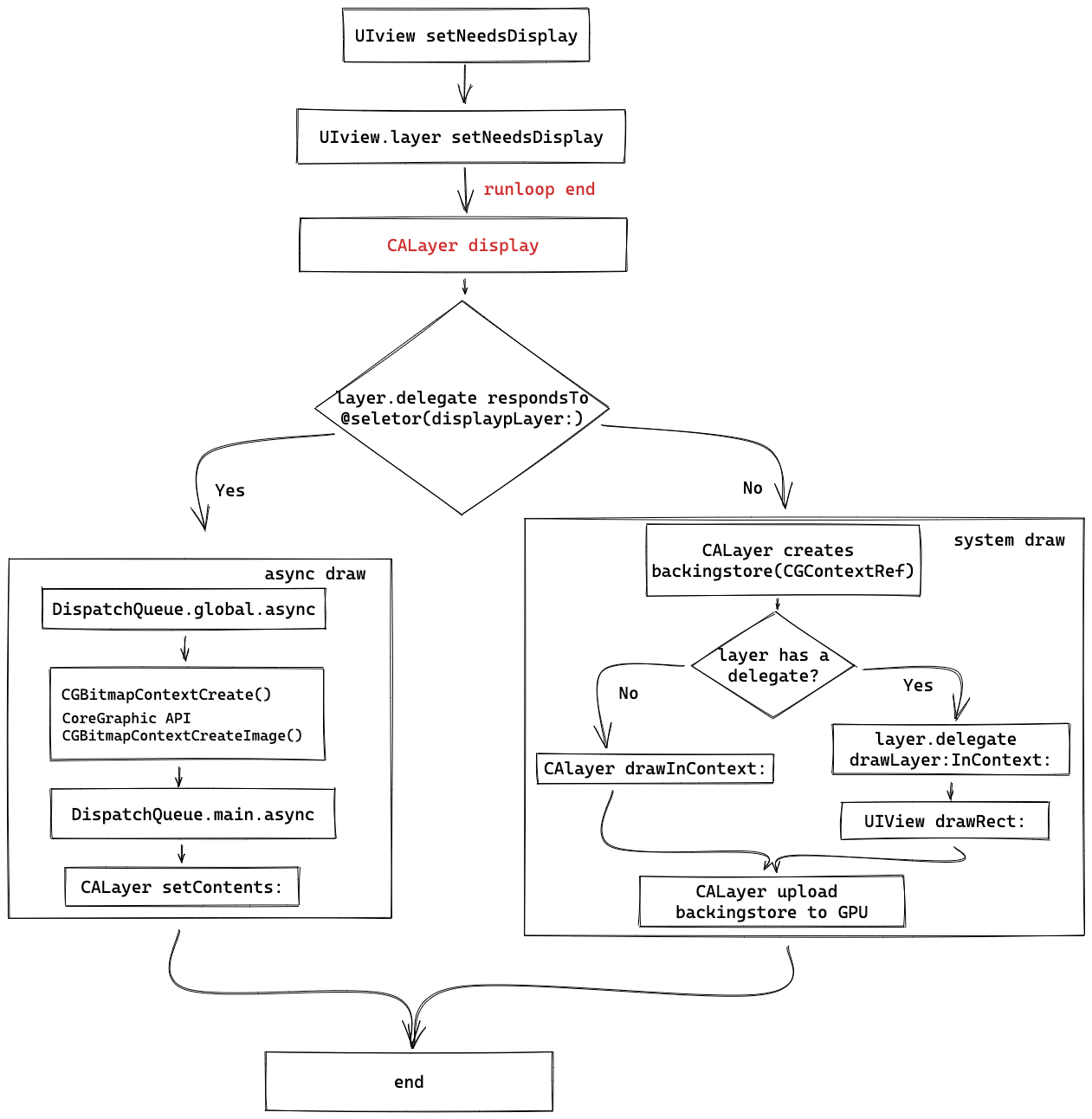
- 调用 view 的
setNeedsDisplay之后,会调用 layer 的setNeedsDisplay方法。
- 在 runloop 结束之后会调用 CALayer 的
display方法。
- 此时,我们可以通过在 View 中重写
displayLayer:方法来实现异步绘制。
- 如果没有实现
displayLayer:方法,则继续系统的绘制流程。
- 系统绘制会根据 layer 是否有 view 来承载进入不同的方法。
- 我们可以在 UIView 的
drawRect:方法中实现我们的内容绘制。
- 最终将绘制好的 bitmap 经由 CoreAnimation 提交给 GPU 进行渲染,也就是我们上面 Commit Transaction 之后的流程。
知道了这两个函数的区别,我们就可以根据需要来开发,如果追求性能,可以使用 frame 来布局,或者使用异步渲染来提高渲染速度,Texture 框架就是这么做的。
离屏渲染
首先了解两个概念,On-Screen Rendering,意为当前屏幕渲染,指的是 GPU 的渲染操作是在当前用于显示的屏幕缓冲区进行的。Off-Screen Rendering,意为离屏渲染,指的是 GPU 在当前屏幕缓冲区外新开辟的一个缓冲区进行渲染操作。通俗来说,就是我们指定了 UI 视图的某些属性,导致了它在未预合成之前不能用于当前屏幕上直接显示的时候,就会触发离屏渲染。
通常的渲染流程是这样的,App 通过 CPU 和 GPU 的合作,不停地将内容渲染完成放入 Framebuffer 帧缓冲器中,而显示屏幕不断地从 Framebuffer 中获取内容,显示实时的内容:

离屏渲染是这样的,与普通情况下 GPU 直接将渲染好的内容放入 Framebuffer 中不同,需要先额外创建离屏渲染缓冲区 Offscreen Buffer,将提前渲染好的内容放入其中,等到合适的时机再将 Offscreen Buffer 中的内容进一步叠加、渲染,完成后将结果切换到 Framebuffer 中:

常用的优化方式
知道了渲染的原理之后,我们就可以在开发中找到一些可以优化的点,减少卡顿和掉帧。
- CPU 层面
- 在子线程中操作对象的创建,销毁等。
- 避免在 Cell 复用的过程中操作 View 的添加和销毁,尽量使用 Hidden 来隐藏和展示。
- 预排版,提前计算好布局和文字高度,同时可以放在子线程中去做。
- 预渲染,文本异步绘制,图片的编解码。
- GPU 层面
- 尽量避免离屏渲染。
- 减少 UIView 层级,对于轻量级且不需要交互的 View,使用 Layer 实现。
对于优化页面流畅性,GitHub - TextureGroup/Texture: Smooth asynchronous user interfaces for iOS apps. 做的非常不错,内部的原理和优化方案值得好好学习。
评测界面流畅度
我们要明确我们流畅性指标是什么,对于绝大部分的 app,有一个通用的标准:
- 每秒 60 帧,在最新的机型已经支持每秒 120 帧。
- 对于 CPU 和 GPU 负载较低,节省电池。
- 离屏渲染,越少越好。
- 混合视图,越少越好。
使用 Xcode 自带的工具以及CADisplayLink,runloop等方案我们可以来测量界面的流畅度以及以上的几个指标。
- Instruments
通过 Instruments 的metal System Trace工具,我们可以录制我们的操作和界面的滚动,之后观察frame rate,检测是否有卡顿现象。
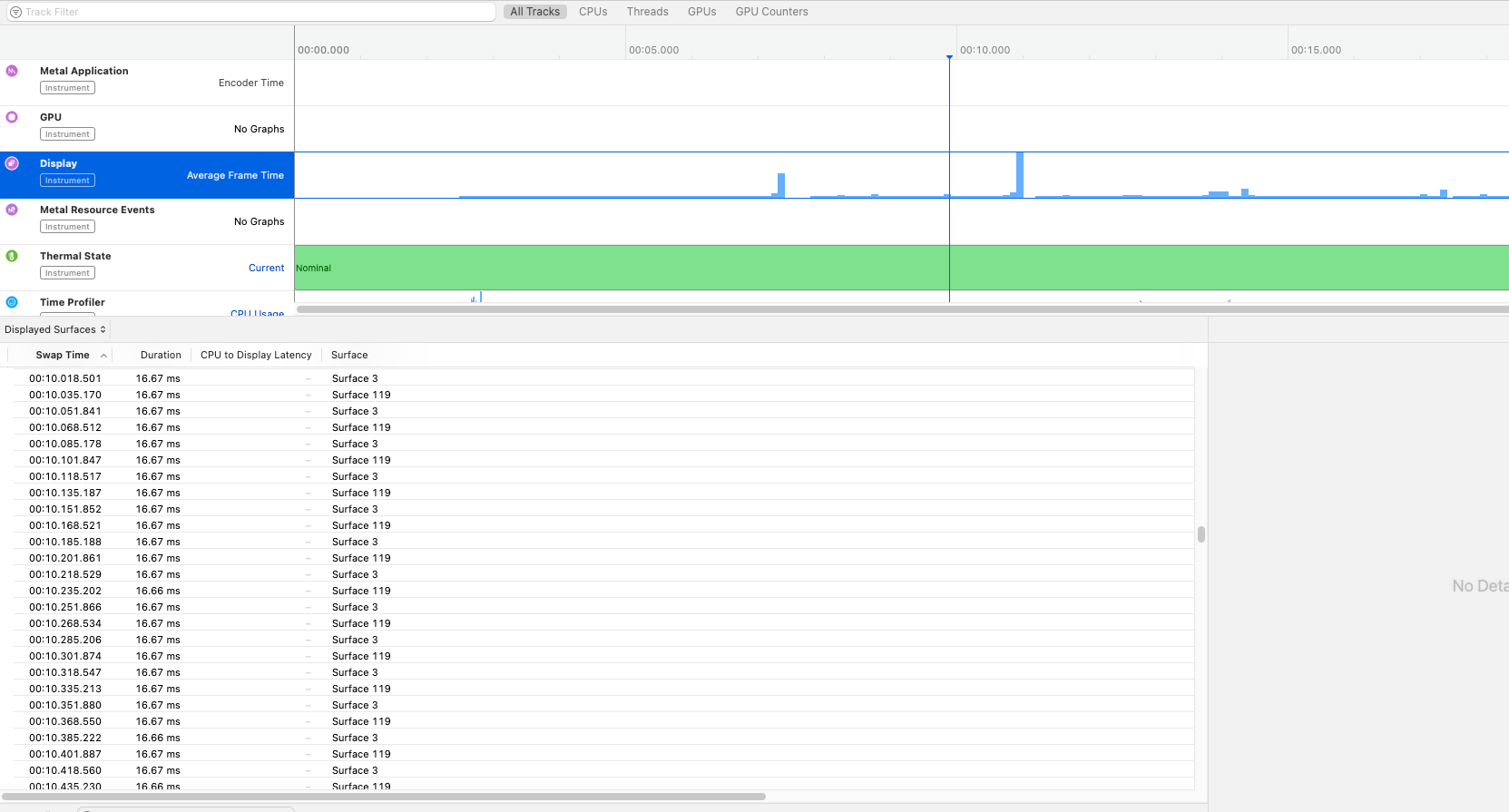
- Simulator
使用模拟器的颜色高亮,可以检测到是否存在离屏渲染或者混合图层等。
- CADisplayLink
向主线程的 RunLoop 的添加一个 commonModes 的 CADisplayLink,每次屏幕刷新的时候都要执行 CADisplayLink 的方法,所以可以统计 1s 内屏幕刷新的次数。
- 子线程 Ping
创建一个子线程通过信号量去 ping 主线程,因为 ping 的时候主线程肯定是在
kCFRunLoopBeforeSources 和 kCFRunLoopAfterWaiting 之间。每次检测时设置标记位为 YES,然后派发任务到主线程中将标记位设置为 NO。接着子线程沉睡超时阙值时长,判断标志位是否成功设置成 NO,如果没有说明主线程发生了卡顿,详细的原理和实现可以参考 使用RunLoop原理监控卡顿。参考文档:




YYAsyncLayer
ibireme • Updated Aug 18, 2023




- Giscus