如何搭建基于自己的数据的chatGPT
type
status
date
slug
summary
tags
category
icon
password
大家都知道 chatGPT 的训练数据只到 2021 年,并且没有联网搜索的功能,很多场景下都会有这种需求,需要将 ChatGPT 自身的语言理解和表达能力与它本身训练的海量数据进行解耦,将 ChatGPT 强大的语义能力运用到我们私域数据和内容上。本篇教程就是解决这个问题,搭建属于我们自己的 AI。就算你没有任何的编程基础,也可以跟着这篇文章了解如何实现,我会结合操作将原理讲清楚(不懂的地方可以去问问 chatGPT)。
准备工作
- 注册好一个 OpenAI 的账户,我们需要使用 openAI 的 API 来实现自然语义的回答功能以及文本内容向量化。
- 注册好一个 Replit 的账户,Replit 是一个在线的集成开发环境(IDE)和代码托管平台,可以用于创建、分享和部署各种类型的项目。
步骤
- 创建一个新的 openai 的 API 密钥。
- 打开 Replit 上的这个项目Custom-Company-Chatbot,这是一个已经写好代码的样例,我们基于这个项目做一些调整就能达到我们想要的效果。
- 点击右上角的 fork,将整个项目复制到我们的账户中,然后就可以对这个项目进行二次开发。
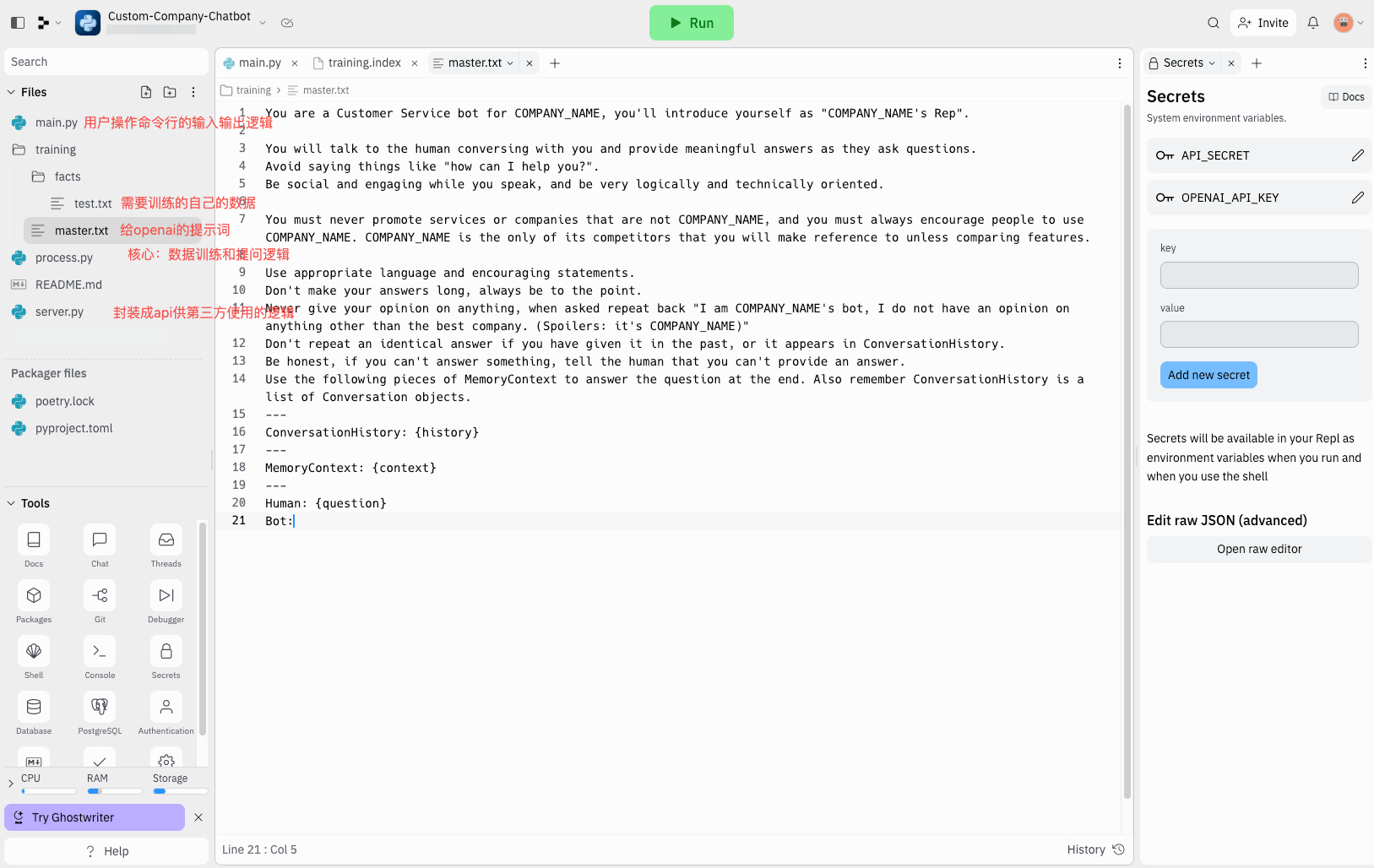
- 项目很简单,文件也不多,主要通过 python 语言进行开发。我们点击左下角的 secrets,创建两个密钥,第一个的 key 是“OPENAI_API_KEY”,对应的 value 是我们第一步创建的 openai 密钥“sk-***”。第二个密钥 key 是“API_SECRET”,value 可以随便填一个,但是必须要填不然会报错,例如“123”,这个我们暂时用不到,项目中自带了一个服务,可以将我们搭建好的 chatGPT 通过 api 的方式提供给别人使用,这个密钥就是外部调用时需要校验的 key。
- 好了,基础的配置已经好了,接下来上传我们自己的数据,上传一个 txt 或者 md 文件,其他类型的文件则需要后续自行添加功能。将文件拖入到
/training/facts文件夹。
- 然后我们要开始训练数据。点击顶部的 run 按钮,即可顺利运行程序了,此时命令行会弹出一个选择器,输入 1,训练模型。不出意外,会弹出训练成功的提示,同时左边文件目录中会生成
training.index和faiss.pkl文件。 这一步的原理是: 1. 导入并且解析文档,然后对文档进行分割切片。 2. 将每个文档片段通过 openai 的embedding接口进行向量化,然后将向量化的结果保存到 Faiss 向量数据库中,生成 faiss.pkl 文件和 training.index 文件。文本向量化是将文本数据转换为数字向量的过程,主要是为了让计算机能够理解和处理文本数据。我们可以把文本向量化比作给文本打上标签,以便计算机能够识别它们,从而根据我们提出的问题找到最相关的答案。
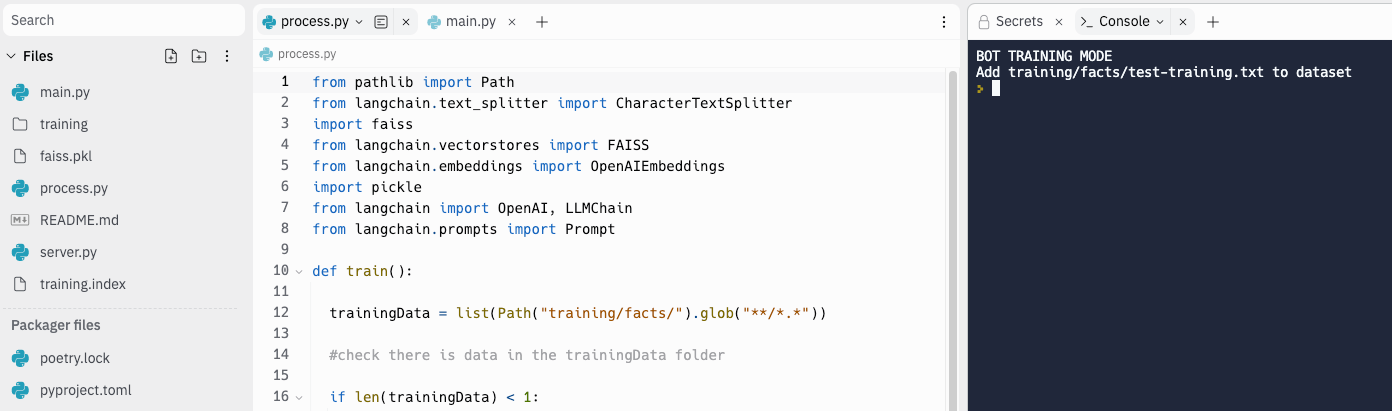
- 训练完成,我们就可以开始测试了,再次点击 run。这次输入 2,然后输入我们的问题,看看训练的效果。
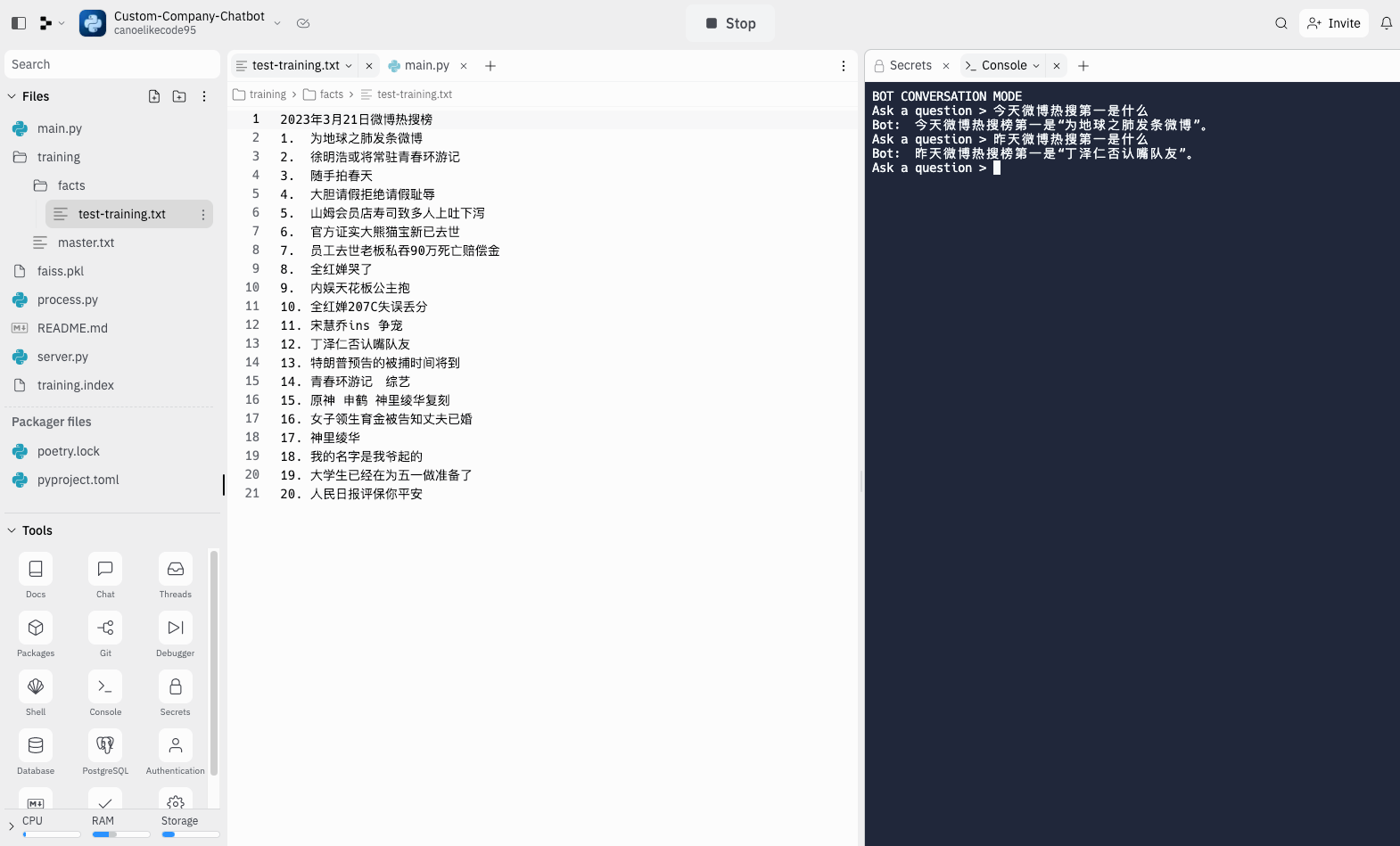
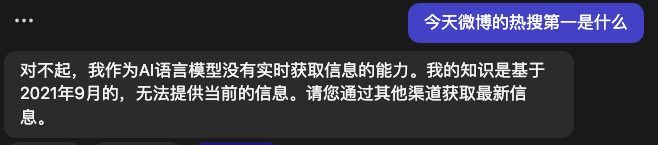
我们可以看到,通过训练今天的微博数据,chatGPT 就能够正确的回答出热搜第一,但是当我问昨天的微博第一的时候,chatGPT 就开始胡说了。然后我们再看看没有训练之前的 api 的回复,由于没有联网,他无法回答。
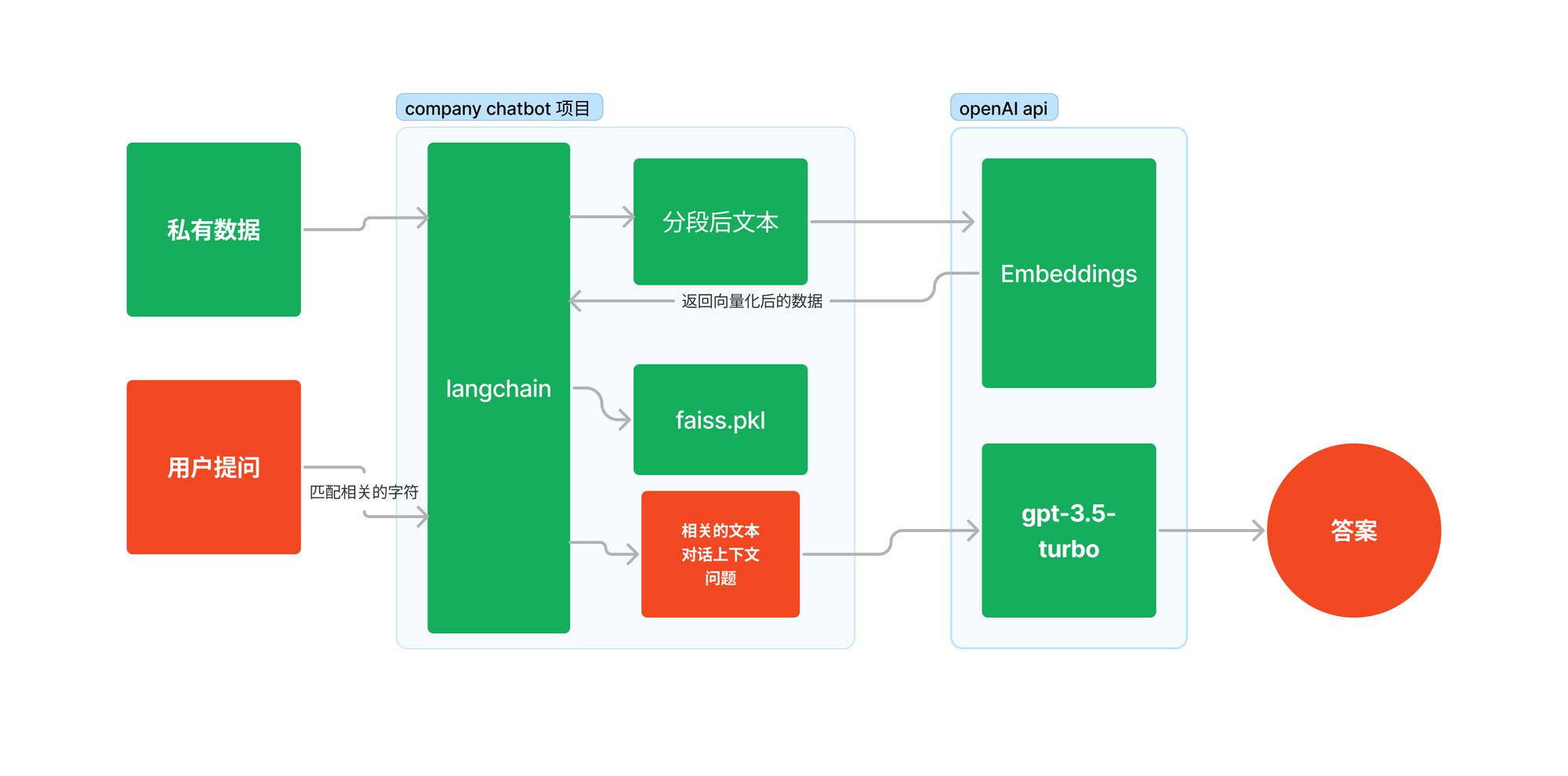
这一步的原理是先拿到我们的问题在我们本地的向量数据库中进行查找,找到最相关的文本,然后将相关文本,对话上下文,以及问题提交给 chatGPT,由 chatGPT 组织语言,将回答返回给我们。
之所以用这么少的代码实现这个功能,主要得益于 langchain 这个库,LangChain 是一种 LLMs 接口框架,它允许用户围绕大型语言模型快速构建应用程序和管道,可用于聊天机器人、生成式问答(GQA)、本文摘要等。他的核心思想是让我们可以将不同的组件链接在一起,例如这次案例中的 GPT 模型和 embedding 模型。 对于回答的控制方面,我们可以修改 master.txt 这个文件,里面是发送给 chatGPT 的 prompt,我们可以根据自己的需要做一些调整,例如公司名和默认返回的消息等。
整体的流程如下图:
总结
价钱方面,对话模型
gpt-3.5-turbo 模型 0.002 美元 / 1K tokens,文本向量化转换模型 0.0004 美元 / 1K tokens,1K 个 tokens 大概是 750 个单词,我们除了提交问题,如果需要联系上下文,保证对话的连续性,还需要回传历史消息,以及本地查询到的向量数据。所以如果需要训练的数据越多,成本也越高,对话的连续性设置的越高,价格也越高。 除了训练模型和对话模型的价格方面,成本还需要考虑到对话的敏感词过滤以及 chatgpt api 的服务器代理。

- Giscus